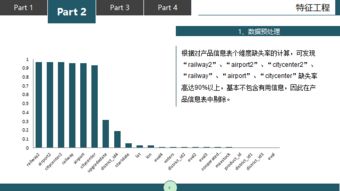
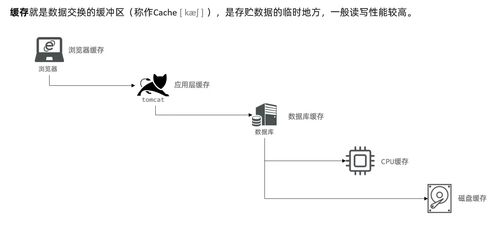
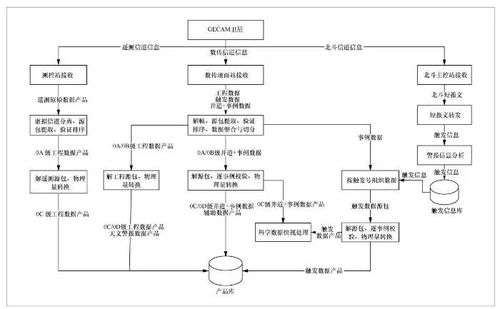
Cobar 關系型數據的分布式處理系統解析
隨著數據量的爆炸式增長,傳統單機數據庫在處理海量數據時逐漸暴露出性能瓶頸。關系型數據庫作為企業核心數據存儲的基石,其分布式改造需求日益迫切。Cobar正是在這一背景下應運而生,它是一個基于MySQL協議的關系型數據分布式處理系統,由阿里巴巴開源,旨在解決大規模數據存儲與訪問的挑戰。
一、Cobar的核心架構與設計原理
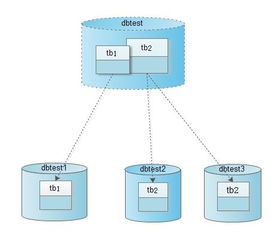
Cobar采用典型的代理模式架構,位于應用層與數據庫層之間。其主要組件包括:Cobar Server(代理服務器)、數據節點(DataNode)和MySQL實例。Cobar Server接收應用端的SQL請求,根據預定義的分片規則進行解析、路由和轉發,將查詢分發到后端多個MySQL實例上執行,最后合并結果返回給客戶端。這種架構實現了對應用透明的數據分片(Sharding),使得業務邏輯無需關心底層數據的分布細節。
分片策略是Cobar的核心特性之一。它支持基于范圍、哈希或枚舉等多種分片算法,允許開發者根據業務特點(如用戶ID、時間范圍等)靈活定義數據分布規則。例如,可以按用戶ID的哈希值將用戶表分散到多個數據庫,有效避免了單點數據過熱的問題。
二、數據處理流程與關鍵特性
在數據處理方面,Cobar展現了強大的能力:
- SQL解析與路由:Cobar能夠解析復雜的SQL語句,識別涉及的分片鍵,并將查詢精準路由到相關分片。對于跨分片的查詢(如多表JOIN或全表掃描),Cobar支持將查詢分發到所有分片并行執行,再通過結果聚合返回,顯著提升了查詢效率。
- 事務管理:Cobar支持分布式事務的弱一致性處理。對于單分片事務,它直接委托給底層MySQL的ACID保證;對于跨分片事務,則通過兩階段提交(2PC)協議協調,確保數據的一致性。
- 讀寫分離與負載均衡:Cobar可以配置主從復制架構,將寫操作定向到主庫,讀操作分攤到多個從庫,既提高了系統吞吐量,也增強了可用性。
- 連接池與故障轉移:Cobar維護了與后端數據庫的連接池,減少了連接開銷。當某個MySQL節點故障時,它能自動檢測并切換到備用節點,保障服務連續性。
三、Cobar的應用場景與優勢
Cobar尤其適用于高并發、大數據量的互聯網業務場景,如電商交易、社交網絡和日志分析等。其優勢主要體現在:
- 水平擴展能力:通過增加數據節點,系統可以線性提升存儲容量和處理性能。
- 對應用透明:應用程序幾乎無需修改代碼,只需調整數據源配置即可接入分布式環境。
- 兼容MySQL生態:完全兼容MySQL協議和語法,現有基于MySQL的工具和驅動可以無縫銜接。
四、挑戰與演進
盡管Cobar在分布式處理上表現卓越,但也面臨一些挑戰。例如,跨分片事務的性能開銷較大,復雜查詢的優化仍有提升空間。隨著技術的發展,Cobar的后續演進版本(如MyCat等)在分布式事務優化、彈性擴縮容等方面做了進一步改進。
Cobar作為早期開源的關系型數據分布式處理系統,為業界提供了重要的架構參考。它通過智能的數據分片和透明的代理機制,有效解決了關系型數據庫的擴展性問題,至今仍在許多企業系統中發揮著關鍵作用。對于尋求數據庫水平擴展的團隊而言,理解Cobar的設計思想與實踐經驗,依然是構建高性能分布式數據平臺的重要基礎。
如若轉載,請注明出處:http://m.otklc.cn/product/82.html
更新時間:2026-02-19 02:02:26